How do we define homelessness in large health care data? Identifying variation in composition and comorbidities
Abstract
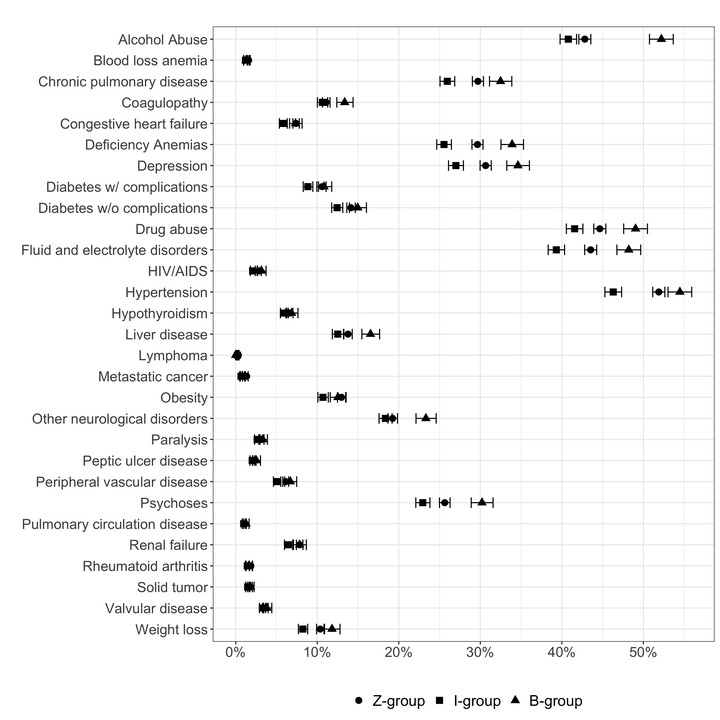
Limited research exists on the health of the homeless population, and often relies on large health care datasets and varied methods, with little work to understand how the choice of measurement, such as an address-based indicator versus diagnosis code, affects the estimates of demographics and comorbidity burden of this population. Using state-wide hospital discharge data, we identified homeless individuals three ways: via ICD-10 Z59.0, an administrative indicator, and those with both. From 2,427,549 discharges, 17,479 individuals were identified via only Z-code, 9183 via only the indicator, and 4578 had both. There were differences in the race, sex, payer, and admission type between the groups. Similarly, comorbidity profiles were different, with the differences reaching 11.4% for alcohol abuse. The difference in the size, composition, and comorbidities between these groups suggests that researchers, clinicians, and policy experts should be wary of current methods to identify homeless individuals and continue to improve capture of this determinant of health. Simply, if we are unable to accurately identify the group of interest and their potential health needs we are equally unable to effectively intervene and provide appropriate and relevant care.
Wyatt P. Bensken, PhD
Research Investigator & Adjunct Assistant Professor of Population and Quantitative Health Sciences
My expertise is in the use of complex health care data, paired with traditional statistical and novel machine learning approaches, to identify opportunities to improve health, health care, and health outcomes for all.